Models¶
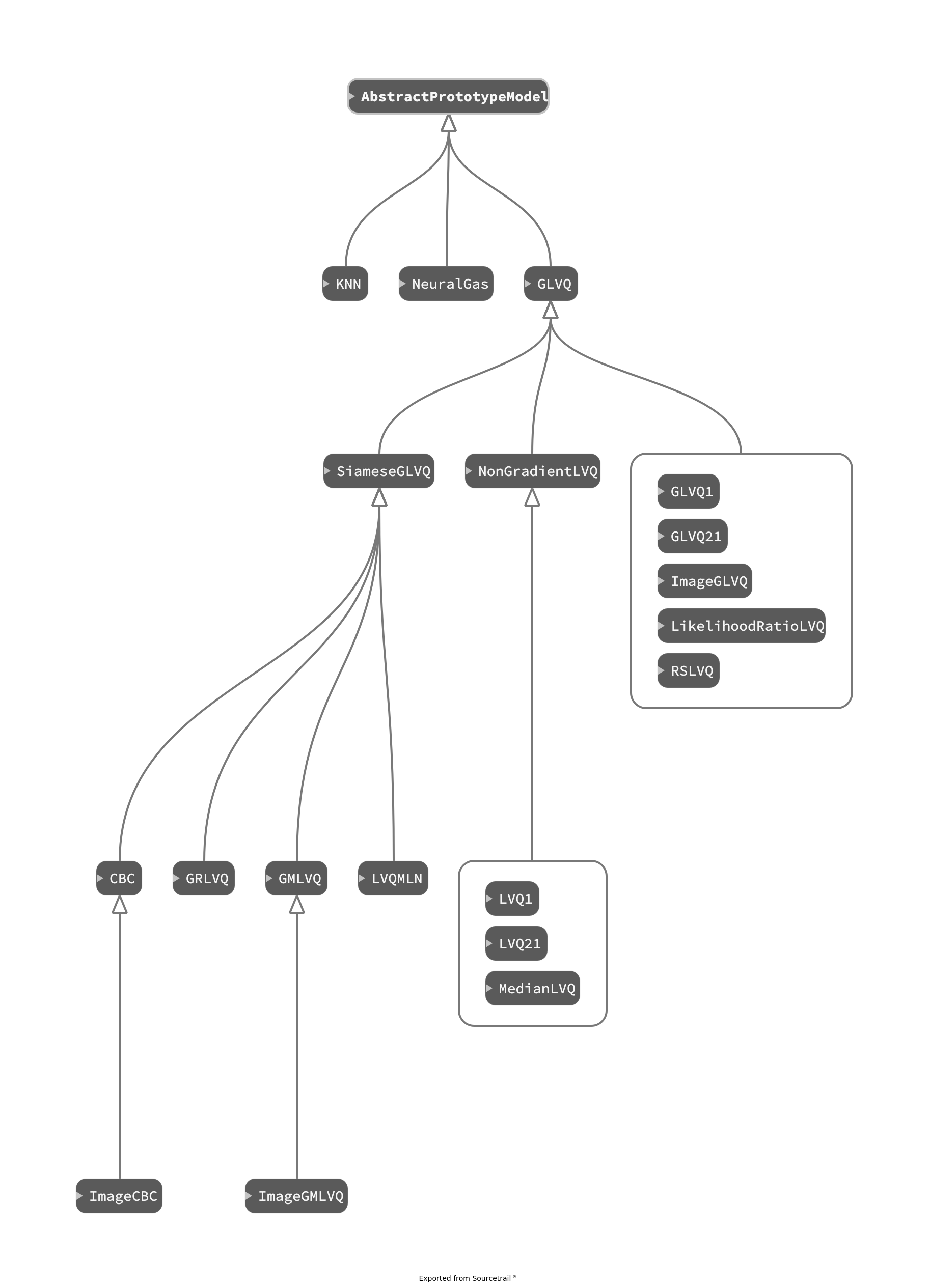
Unsupervised Methods¶
Classical Learning Vector Quantization¶
Original LVQ models introduced by Kohonen [1989]. These heuristic algorithms do not use gradient descent.
It is also possible to use the GLVQ structure as shown by Sato and Yamada [1996] in chapter 4. This allows the use of gradient descent methods.
Generalized Learning Vector Quantization¶
Sato and Yamada [1996] presented a LVQ variant with a cost function called GLVQ. This allows the use of gradient descent methods.
The cost function of GLVQ can be extended by a learnable dissimilarity. These learnable dissimilarities assign relevances to each data dimension during the learning phase. For example GRLVQ [Hammer and Villmann, 2002] and GMLVQ [Schneider et al., 2009] .
The dissimilarity from GMLVQ can be interpreted as a projection into another dataspace. Applying this projection only to the data results in LVQMLN
The projection idea from GMLVQ can be extended to an arbitrary transformation with learnable parameters.
Probabilistic Models¶
Probabilistic variants assume, that the prototypes generate a probability distribution over the classes. For a test sample they return a distribution instead of a class assignment.
The following two algorihms were presented by Seo and Obermayer [2003] . Every prototypes is a center of a gaussian distribution of its class, generating a mixture model.
Villmann et al. [2018] proposed two changes to RSLVQ: First incooperate the winning rank into the prior probability calculation. And second use divergence as loss function.
Classification by Component¶
The Classification by Component (CBC) has been introduced by Saralajew et al. [2019] . In a CBC architecture there is no class assigned to the prototypes. Instead the dissimilarities are used in a reasoning process, that favours or rejects a class by a learnable degree. The output of a CBC network is a probability distribution over all classes.
Visualization¶
Visualization is very specific to its application. PrototorchModels delivers visualization for two dimensional data and image data.
The visulizations can be shown in a seperate window and inside a tensorboard.
Bibliography¶
- HV02
Barbara Hammer and Thomas Villmann. Generalized relevance learning vector quantization. Neural Networks, 15(8):1059–1068, 2002. doi:https://doi.org/10.1016/S0893-6080(02)00079-5.
- Koh89
Teuvo Kohonen. Self-Organization and Associative Memory. Springer Berlin Heidelberg, 1989. doi:10.1007/978-3-642-88163-3.
- SHR+19
Sascha Saralajew, Lars Holdijk, Maike Rees, Ebubekir Asan, and Thomas Villmann. Classification-by-components: probabilistic modeling of reasoning over a set of components. In Advances in Neural Information Processing Systems, volume 32. 2019. URL: https://proceedings.neurips.cc/paper/2019/file/dca5672ff3444c7e997aa9a2c4eb2094-Paper.pdf.
- SY96(1,2)
Atsushi Sato and Keiji Yamada. Generalized learning vector quantization. Advances in neural information processing systems, pages 423–429, 1996. URL: http://papers.nips.cc/paper/1113-generalized-learning-vector-quantization.pdf.
- SBH09
Petra Schneider, Michael Biehl, and Barbara Hammer. Adaptive Relevance Matrices in Learning Vector Quantization. Neural Computation, 21(12):3532–3561, 12 2009. doi:10.1162/neco.2009.11-08-908.
- SO03
Sambu Seo and Klaus Obermayer. Soft Learning Vector Quantization. Neural Computation, 15(7):1589–1604, 07 2003. doi:10.1162/089976603321891819.
- VKSV18
Andrea Villmann, Marika Kaden, Sascha Saralajew, and Thomas Villmann. Probabilistic learning vector quantization with cross-entropy for probabilistic class assignments in classification learning. In Artificial Intelligence and Soft Computing. Springer International Publishing, 2018.